フレア処理を高速化した話
この記事はQualiArts Advent Calendar 2020の20日目の記事になります。
昨日は 無料のDataformでBigQueryにおけるデータ加工のDXを改善して幸せになろう - Qiita でした
はじめに
現在開発中のプロジェクトではUniversalRenderPipeliene(以下URP)を使用しているためレンズフレアを使用することができません

LensFlareどころかHaloも使用できないため画面にフレアを描画する手段がURPには用意されていません。
他にもかなり機能制限があるので比較を見たい方はこちら
docs.unity3d.com
そこでアセットストアでLensFlareを探すと何個か引っかかるのですが意外と存在しない…
https://assetstore.unity.com/?q=Lens%20Flare&orderBy=0
この中で一番細かく設定できそうだったProFlareを導入したのですが、大量のフレアを出すとCPU,GPU共に負荷が高く、実機でボトルネックとなってしまったのでSRP用に描画部分を作り直すことにしました
このアセット自体は非常に高品質なレンズフレアを作成できるためちょっと使う分であればオススメです
ここからは実際に負荷計測から試してみます
Unity2020.1.16, UniversalRenderPipeline8.x.xを使用しています
初期状態で負荷を計測してみる
ProFlareを100個空間に生成し、画面内に1000個ほどのスプライトが表示されている状態で実行したときのPixel3aの負荷を比較していきます
検証端末
Pixel3aのSoCは Snapdragon 670 が使用されており、Antutuスコアは
総合 17.5万点
GPU 4.0万点
となっています
参考: 【11/1最新】Antutuベンチマークスコア、Soc別総まとめ | telektlist
これは一概に比較は出来ないですが iPhone6Sと同程度 の性能のため低スペック端末の代表として参考にしています
実行結果

見るからに負荷の高そうな見た目となっています
まずは何もチューニングしない状態での負荷が↓こちらです
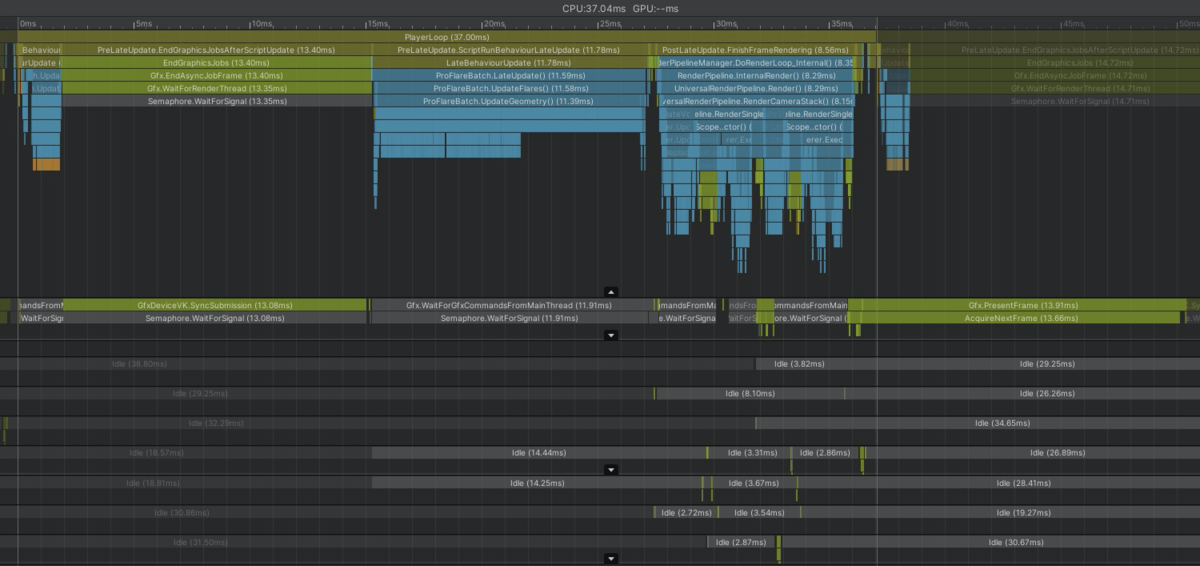
※CPUに関しては内訳を調べるためにDeepProfileで実行しているため、実際よりも負荷が高くなっています
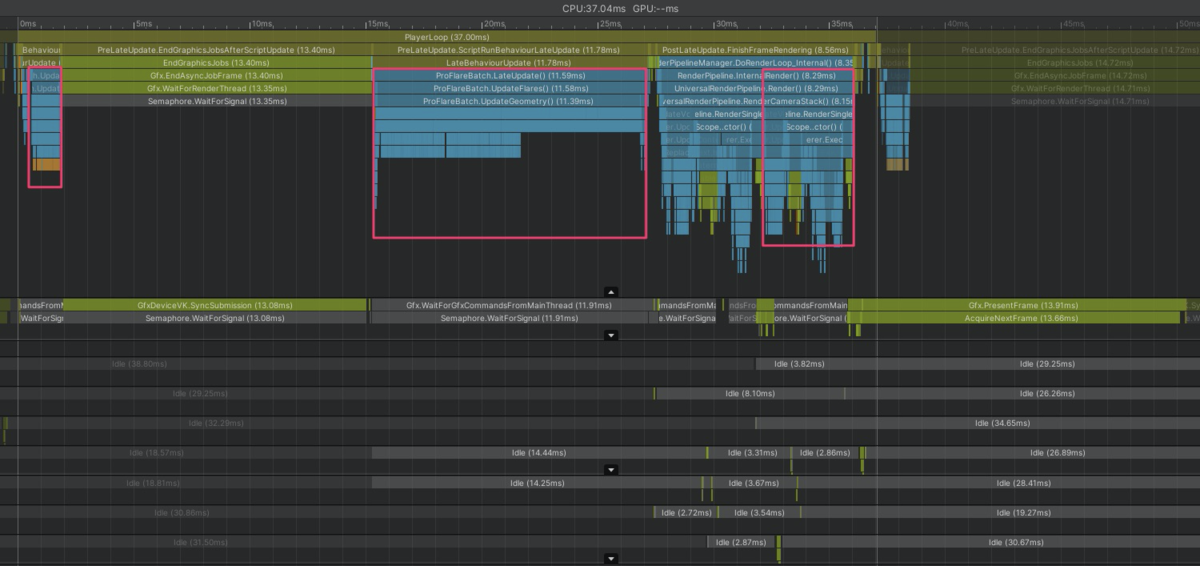
赤いところが全てProFlareのCPU処理となっています
Update 0.93ms
LateUpdate 11.58ms
Rendering 3.55ms
計 16.06ms
やばい
GPUは具体的な内訳が分からないですが13msは使用しているようです
またSRPに完全対応していないので別のカメラで撮影しており無駄にCPU負荷も持ってかれています
何が重いのか
BatchUpdate
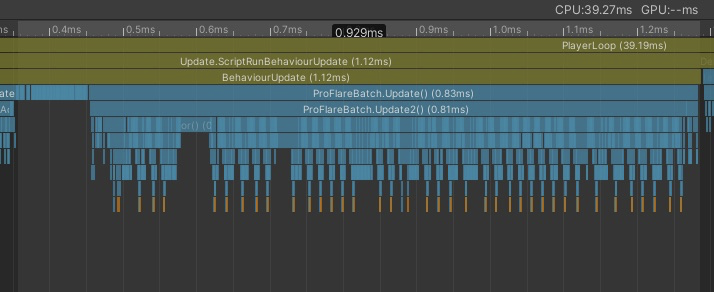
ここではRaycastを行いColliderに隠れているかどうかを判定する処理が入っています
Flareの数が増えるほどRaycastの量が増えて負荷が増大していきます
BatchLateUpdate
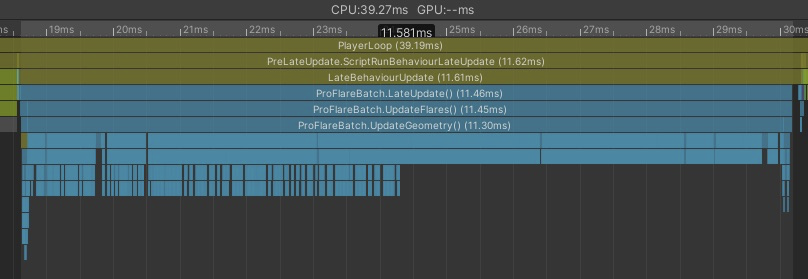
ここでは座標更新とメッシュ更新の処理が含まれています
負荷の大部分はここです
Rendering
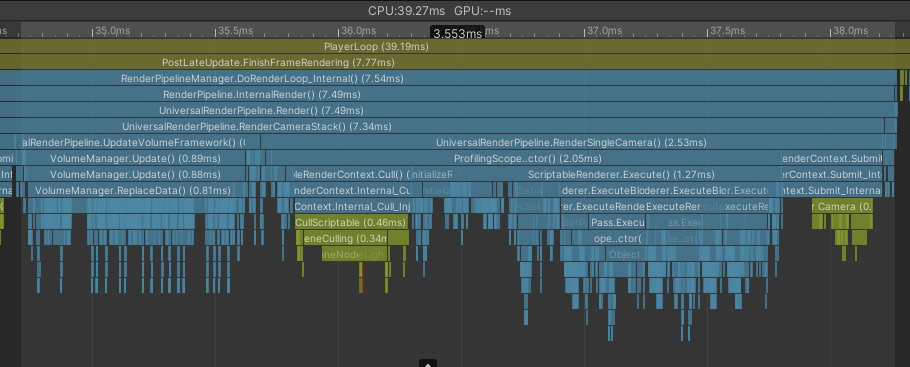
Overlayカメラで描画しているためVolume更新処理や描画リクエストがここになるのですがカメラが一台増えるだけでかなりの負荷を持ってかれます
これらが主な負荷の原因となっているのでここからは実際にパフォーマンスチューニングをしていきます
ProFlareの簡単な設計
高速化の前にそもそもProFlareがどういう構造になっているか分からないと思うので簡単な図にしました

図が下手くそですみません、、
メッシュ生成を行うProFlareBatchは複数のProFlareを管理し、ProFlareは複数のElementを管理しています
さらにElementにはMultiという機能があり、同じ画像をランダムに複数個簡単に並べることも可能なので実際に管理するQuadの数は1000個をゆうに超えます
これを直列で実行していたので負荷が高いのは当たり前です
LateUpdate高速化
まず一番負荷が高いLateUpdateから高速化します
大部分はElementの頂点変形と更新が原因のため可能な限りCPUでの処理を減らしていきます
また、後述しますが今回はMeshは作成せず直接シェーダで頂点変換するため、連携しやすいRendererFeature内で処理するようにします
RendererFeatureはScriptableRenderPipelineから追加された概念で、カスタムした描画処理を簡単に追加することが出来ます
細かい説明はここでは省きますが、任意の描画イベントでCommandBufferを簡単に実行することができます
docs.unity3d.com
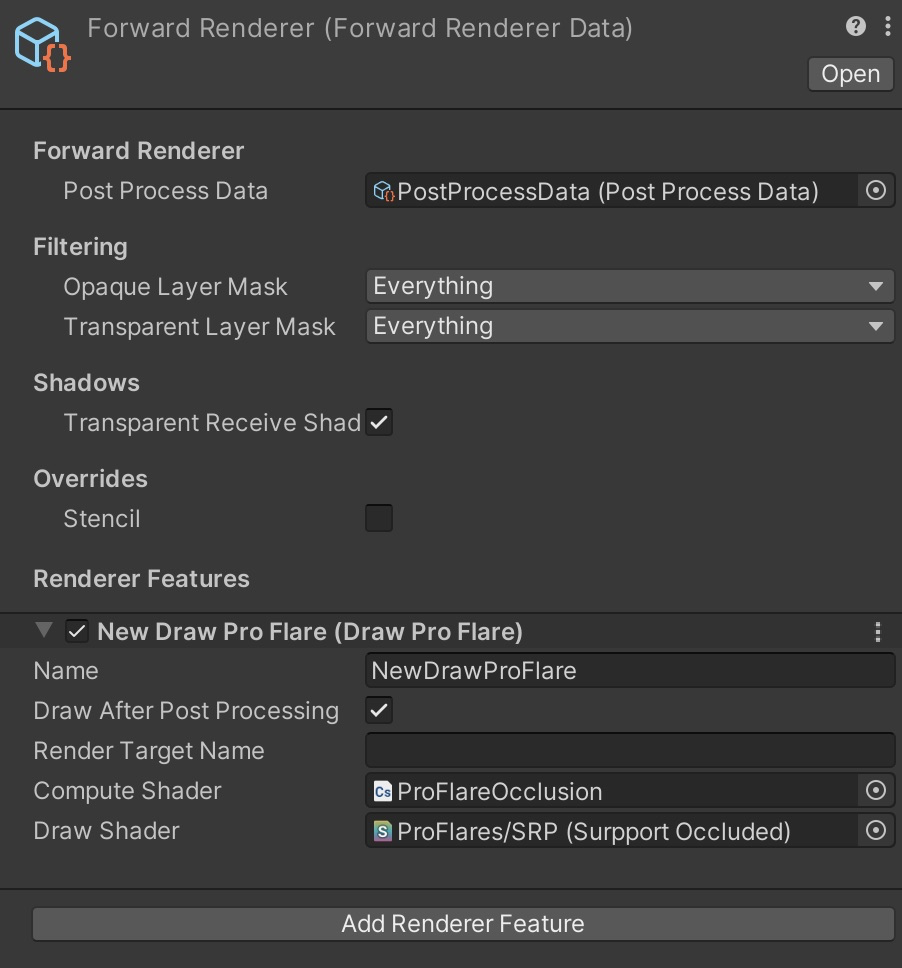
Flareの更新
一番お手軽な高速化といえばBurstJob化ですが、複数のTransformへのアクセスやAnimationCurveが含まれているため、無理にJob化すると処理が全くの別物になってしまいます
また、Jobに投げるための無駄な処理も増えてしまうので高速化はElement処理に特化したほうがいいと考えました。この辺りのどこまでJob化するかの線引は難しいところです
Flareの座標更新によりカリング結果が分かるため不必要なElementデータをスキップしながら並列に扱いやすようにデータを詰め込みます
以下が格納するコードです(アセットのコードは上げられないので雰囲気だけでも)
void UpdateElementJobData((ProFlareUpdateElementData*) pFlareUpdateElement, Color tintColor, float subScale, float angle, float position) { pFlareUpdateElement->IsMulti = element.type == ProFlareElement.Type.Multi; pFlareUpdateElement->FlareIndex = flareIndex; pFlareUpdateElement->GlobalColor = globalColor; pFlareUpdateElement->TintColor = tintColor; pFlareUpdateElement->AddAlpha = addAlpha; pFlareUpdateElement->MultiplyAlpha = multiplyAlpha; pFlareUpdateElement->Scale = subScale * element.Scale * 0.01f * flare.GlobalScale * finalScale * scaleMulti; pFlareUpdateElement->Size = element.size; pFlareUpdateElement->UseRangeOffset = element.useRangeOffset; pFlareUpdateElement->Position = position; pFlareUpdateElement->OffsetPostion = element.OffsetPostion; pFlareUpdateElement->LensPosition = lensPosition; pFlareUpdateElement->Anamorphic = element.Anamorphic; pFlareUpdateElement->RotateToFlare = element.rotateToFlare; pFlareUpdateElement->RotationSpeed = element.rotationSpeed; pFlareUpdateElement->RotationOverTime = (currentTime * element.rotationOverTime); pFlareUpdateElement->Angle = angle; pFlareUpdateElement->ElementTextureID = element.elementTextureID; }
Flare内のElementをループで回して順次NativeArrayのポインタに格納しています
ここでは最低限の計算のみ行い、ほとんどが値のコピーとなっています
これで並列処理の準備が整いました
Elementの更新
並列処理しやすいようにデータを整形したので実際にJobを作成してElementのオフセットやカラー等の更新を行います
Jobの使い方に関してはさまざまな解説サイトがあるためここでは割愛しますがBurstCompile対応させることで爆速な並列処理が可能になります
IJobParallelForを用いているので32要素を1ブロックとしてScheduleします
_jobHandle = new ProFlareUpdateElementJob { VR_Mode = flareBatchForSrp.VR_Mode, VR_Depth = flareBatchForSrp.VR_Depth, useBrightnessThreshold = flareBatchForSrp.useBrightnessThreshold, BrightnessThreshold = flareBatchForSrp.BrightnessThreshold, OverdrawDebug = flareBatchForSrp.overdrawDebug, InputData = _flareUpdateElementData, FlareElementData = _flareElementsData, UVData = _uvData, }.Schedule(_visibleFlareElementCount, 32, _jobHandle); _jobHandle.Complete();
入力データ構造(殆どがProFlareElementから値をコピーしたもの)
public struct ProFlareUpdateElementData { public bool IsMulti; public int FlareIndex; public Color GlobalColor; public Color TintColor; public float AddAlpha; public float MultiplyAlpha; public float Scale; public Vector2 Size; public bool UseRangeOffset; public float Position; public Vector3 OffsetPostion; public Vector3 LensPosition; public Vector3 Anamorphic; public bool RotateToFlare; public float RotationSpeed; public float RotationOverTime; public float Angle; public int ElementTextureID; }
出力データ構造 48byte (シェーダで扱いやすくしたデータサイズを極力小さくしたもの)
[StructLayout(LayoutKind.Sequential)] public struct ProFlareElementData { public uint flareIndex; // シェーダ内でFlareのIndexが取れるように public Color32 color; // カラー public float2 scale; // スケール public float3 offset; // オフセット public float angle; // 回転角度 public float4 uv; // UVRect }
出力データはシェーダで読み込みたいので最小限になるように変換しています
これで元の複雑なパラメータをGPUで扱いやすい小さなデータ構造に変換することが出来ました
Jobの結果をShaderで読めるようにComputeBufferに格納
NativeArrayに入ったデータ構造はもちろんGPUでは読めないためComputeBufferに変換します
ComputeBufferはクラス名的にComputeShader用に見えますが、VertexShaderでも読むことが出来るので非常に便利です
ただし、GPU世代に制限があるためシェーダ定義に↓これを定義したほうがいいです
#pragma target 4.5
Vertexシェーダから読むためにはOpenGLES3.1世代(ComputeShader)に対応したGPUが必要なためです
public void UpdateComputeBuffer(CommandBuffer cmd) { cmd.SetComputeBufferData(_flareElementsBuffer, _flareElementsData); }
ComputeBufferの更新自体は簡単でCommandBufferでSetComputeBufferDataを呼び出すだけです
第2引数にはC#上で扱えるリストなら大抵入るので困ることはないと思います
ここではJobとの兼ね合いもありNativeArrayの内容を丸ごとComputeBufferにコピーしています
docs.unity3d.com
ここまでの結果
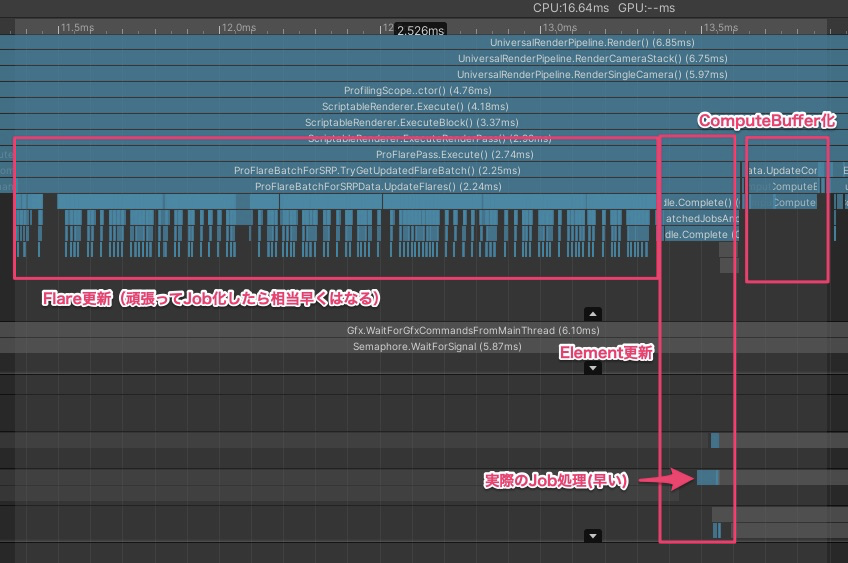
頂点の更新以外を高速化した時点のDeepProfile結果がこれです↓
11.58ms -> 2.53ms
FlareもJob化すればよかったと若干後悔しましたが、ほぼコード変えずに移行できたので良しとします
Update高速化
UpdateではRaycastを行いFlareが隠れているかどうかを行っていますが、ComputeShaderを使えばGPUでチェックすることができるので実装を変更してみます
ComputeShader
ComputeShaderは通常のシェーダと違い数値計算を高速に実行することが出来ます
iOSではMetal以上、AndroidではOpenGLES3.1以上が必要ですが現状のシェアを考えるとそろそろ使っていいのかなという所感です
解説はUnity公式が一番わかり易いです
docs.unity3d.com
ComputeShader用にFlareデータを作成する
前項でもShaderで扱えるようにComputeBufferを使用していましたがComputeShaderを使用する場合もC#からのコピーが必要です
ComputeShader入力データ構造
[StructLayout(LayoutKind.Sequential)] public struct ProFlareInputData { public float3 lensPosition; // 画面座標,奥行き public float occlusionScaleSpeed; // 遮蔽時のスケール変化速度 public float occlusionBrightnessSpeed; // 遮蔽時の輝度変化速度 }
ComputeShader出力データ構造
[StructLayout(LayoutKind.Sequential)] public struct ProFlareProcessData { public uint flags; // カリング状態 public float occlusionScale; // 現在のスケール public float occlusionBrigtness; // 現在の輝度 }
実際のComputeShaderコードです
#pragma kernel Update // C#上での構造体と同じ型を定義したファイルをインクルード #include "ProFlareInput.hlsl" // 書き込む必要がないデータはStructuredBufferで定義します StructuredBuffer<ProFlareInputData> _InputBuffer; // 書き込みも必要なデータはRWStructuredBufferで定義します RWStructuredBuffer<ProFlareProcessData> _ProcessBuffer; // DepthTextureはこのように定義すれば勝手にUnityが入れてくれます Texture2D<float> _CameraDepthTexture; float4 _CameraDepthTexture_TexelSize; // 更新に必要な各種パラメータをまとめてfloat4に // x=cullFlaresAfterTime, y=deltaTime, z=(f-n)/n*f, w=1/f float4 _OcclusionParams; // DepthTextureから距離に変換してFlareの距離と比較して返す関数 uint CheckOccluded(float2 screenPosition, float targetDepth) { // ComputeShaderのテクスチャアクセスはpx単位なので_TexelSizeでスケール float depthBuffer = _CameraDepthTexture[screenPosition*_CameraDepthTexture_TexelSize.zw].r; float depth = 1.0 / (_OcclusionParams.z * depthBuffer + _OcclusionParams.w); return depth < targetDepth ? 1 : 0; } [numthreads(16,1,1)] void Update (uint2 id : SV_DispatchThreadID) { // id.xはFlareのIndexと連動している ProFlareInputData input = _InputBuffer[id.x]; // depthチェックでめり込むので10cmオフセット uint occluded = CheckOccluded(input.lensPosition.xy, input.lensPosition.z - 0.1); ProFlareProcessData process = _ProcessBuffer[id.x]; float occlusionTarget = occluded ? 0 : 1; // だんだんと小さくなったり大きくなったりを実現するためdeltaTimeを使用して値を更新 process.occlusionScale = lerp(process.occlusionScale, occlusionTarget, saturate(_OcclusionParams.y * input.occlusionScaleSpeed)); process.occlusionBrigtness = lerp(process.occlusionBrigtness, occlusionTarget, saturate(_OcclusionParams.y * input.occlusionBrightnessSpeed)); process.flags = occluded; // 計算結果を更新 _ProcessBuffer[id.x] = process; }
このようにComputeShaderではテクスチャアクセスも容易でCっぽい感じで直感的に実装が可能です
また、フレーム間を跨いでの値の更新が可能なため様々な用途に用いることができます
並列処理が可能でデータ構造が大きくない場合は一つの選択肢に入れてもいいのかなと思います
今回はDepthTextureにアクセスできることを利用しているのでCPU,GPUを止めることなく処理を行える利点もあります(ComputeShaderを使用しない場合は描画結果をCPUへ渡す処理が発生し、CPU,GPUを非同期に実行することが難しくなる)
後はRendererFeatureでこのComputeShaderを実行します
// ComputeBufferのコピー flareBatchData.UpdateComputeBuffer(cmd); // ComputeShaderにComputeBufferを指定 cmd.SetComputeBufferParam(_computeShader, _updateKernelIndex, _InputBuffer, flareBatchData.InputBuffer); cmd.SetComputeBufferParam(_computeShader, _updateKernelIndex, _ProcessBuffer, flareBatchData.ProcessBuffer); // x=cullFlaresAfterTime, y=deltaTime, z=(f-n)/n*f, w=1/f var near = camera.nearClipPlane; var far = camera.farClipPlane; cmd.SetComputeVectorParam(_computeShader, _OcclusionParams, new Vector4(_proFlare.cullFlaresAfterTime, _proFlare.DeltaTime, (far - near) / (near * far), 1f / far)); // ComputeShaderを実行 cmd.DispatchCompute(_computeShader, _updateKernelIndex, groupSize, 1, 1);
ComputeShader化した結果
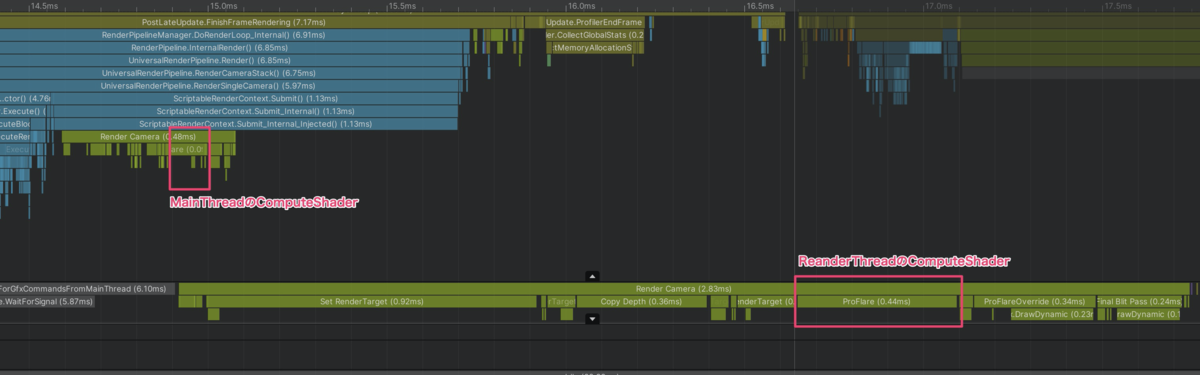
RaycastをやめてDepthTextureで遮蔽判定にしたときのDeepProfile結果がこれです↓
0.93ms -> 0.09ms
RenderThreadに処理が移動したので次フレームのUpdate処理の裏側で走るようになったのが分かると思います
そのためメインスレッドを止める時間としては相当な高速化が実現できています
Rendering高速化
元の処理は別のカメラを用意してそのカメラでメッシュを撮影する昔ながらの方法で実装されていましたが、無駄な処理が非常に多いのでRenderPipelineに組み込んで処理の効率化をします
RendererFeatureでの描画セットアップ
LateUpdateの高速化で使用していますがRendererFeatureを使用することでカメラを増やさずに描画処理等を追加できるので座標更新と同時に描画も行います
ここまでで作成したComputeBufferをMaterialPropertyBlockのSetBufferを使用することでシェーダにセットすることが出来ます
扱いとしてはテクスチャなどと変わらないので特に難しいところはないと思います
Unityが内部でいろいろと環境間の処理を吸収してくれていると思うので感謝しかありません
// ComputeBufferをMaterialPropertyBlockに指定 _materialPropertyBlock.SetBuffer(_ProcessBuffer, flareBatchData.ProcessBuffer); _materialPropertyBlock.SetBuffer(_ElementBuffer, flareBatchData.FlareElementsBuffer); var currentViewMatrix = camera.worldToCameraMatrix; var currentProjMatrix = camera.projectionMatrix; var aspect = camera.aspect; _projMatrix.m00 = 1f / aspect; // VPMatrixをProFlareのカメラと同じにする cmd.SetViewProjectionMatrices(_viewMatrix, _projMatrix); // Meshを使用せずにComputeBufferのみで描画 cmd.DrawProcedural(flareBatchData.IndexBuffer, _modelMatrix, _material, 0, MeshTopology.Triangles, flareBatchData.VisibleFlareElementCount * 6, 1, _materialPropertyBlock); // VPMatrixをもとに戻す cmd.SetViewProjectionMatrices(currentViewMatrix, currentProjMatrix);
Meshを生成しないで描画
通常であればMeshを作成してMeshRendererで描画するのが普通ですがFlareは全てが四角形で構成されるため頂点シェーダで全て処理を行ってみます
そこで使用するのがDrawProceduralメソッドです
このメソッドを使用するとMeshを使用せずにComputeBufferのみで描画することが可能です
docs.unity3d.com
DrawProceduralメソッドには従来から↓のメソッドがあり頂点数に応じて自動で三角ポリゴンを生成して描画してくれます
public void DrawProcedural(Matrix4x4 matrix, Material material, int shaderPass, MeshTopology topology, int vertexCount);
しかし、全然知らなかったのですがGraphicsBufferというものが出来ていたようです
Unity2020.1 以降では ComputeBuffer を使わず GraphicsBuffer を使おう
GraphicsBufferを使用すると三角形のつなぎ方まで指定できます
public void DrawProcedural(GraphicsBuffer indexBuffer, Matrix4x4 matrix, Material material, int shaderPass, MeshTopology topology, int indexCount, int instanceCount, MaterialPropertyBlock properties);
// NativeArrayで4頂点ごとの四角形ができるように作成 _indexData = new NativeArray<int>(maxFlareElementSize * 6, Allocator.Persistent); for (int i = 0; i < maxFlareElementSize; i++) { _indexData[i * 6 + 0] = (i * 4 + 0); _indexData[i * 6 + 1] = (i * 4 + 1); _indexData[i * 6 + 2] = (i * 4 + 2); _indexData[i * 6 + 3] = (i * 4 + 2); _indexData[i * 6 + 4] = (i * 4 + 1); _indexData[i * 6 + 5] = (i * 4 + 3); } // GraphicsBufferにコピー _indexBuffer = new GraphicsBuffer(GraphicsBuffer.Target.Index | GraphicsBuffer.Target.Raw, maxFlareElementSize * 6, sizeof(int)); _indexBuffer.SetData(_indexData);
これによりMeshを用意せずに大量の四角形を描画する準備ができました
さらに引数にIndexCountがあるため動的に描画数を変動させることも簡単になりました
以下が頂点シェーダの一部です
// ComputeShaderと同じようにStructuredBufferでアクセスできます StructuredBuffer<ProFlareProcessData> _ProcessBuffer; StructuredBuffer<ProFlareElementData> _ElementBuffer; // 入力は頂点番号だけ Varyings Vertex ( uint id : SV_VertexID ) { Varyings output = (Varyings)0; // 4頂点ごとにElementを描画するためビットシフトすればElementID ProFlareElementData elementData = _ElementBuffer[id >> 2]; ProFlareProcessData flare = _ProcessBuffer[elementData.flareIndex]; half r = elementData.angle * (PI_Div180); half ct, st; sincos(r, st, ct); half2 scale = elementData.scale; scale *= flare.occlusionScale; half3 offset = elementData.offset; half4 color = GetPackedColor(elementData.color); color.a *= flare.occlusionBrigtness; half4 uvRect = elementData.uv; // 頂点番号から各頂点の値を高速に計算する // 0:00 1,1 zw // 1:01 1,-1 zy // 2:10 -1,1 xw // 3:11 -1,-1 xy uint idx = id & 3; uint bit0 = idx & 1; uint bit1 = (idx >> 1) & 1; half4 vInfo = lerp( half4(1, 1, uvRect.z, uvRect.w), half4(-1, -1, uvRect.x, uvRect.y), half4(bit1, bit0, bit1, bit0)); float3 positionOS = float3((ct * (vInfo.x * scale.x) - st * (vInfo.y * scale.y)), (st * (vInfo.x * scale.x) + ct * (vInfo.y * scale.y)), 0) + offset; VertexPositionInputs vertexInput = GetVertexPositionInputs(positionOS); output.positionCS = vertexInput.positionCS; output.uv = vInfo.zw; output.color = color * (color.a * 3); // 出力はいつもどおり return output; }
描画解像度を下げる
正直GPUにはこれが一番効果的です
RendererFeatureには描画対象のRenderTextureを指定できるので解像度を1/4にしてそこに描画します
引き伸ばされるので画質は悪くなりますがフレアの場合はパット見分からないので下げてしまいます
public override void Configure(CommandBuffer cmd, RenderTextureDescriptor cameraTextureDescriptor) { cameraTextureDescriptor.width >>= 1; cameraTextureDescriptor.height >>= 1; cameraTextureDescriptor.depthBufferBits = 1; cameraTextureDescriptor.msaaSamples = 1; // RenderTextureを取得してこのRendererFeatureの描画対象とする cmd.GetTemporaryRT(_targetId, cameraTextureDescriptor); ConfigureTarget(_targetId); ConfigureClear(ClearFlag.Color, Color.black); }
全て取り込んだ結果
ここまでで全てのチューニングが終わりましたが、具体的な数値を見やすくするためDeepProfileで実行した結果でした
DeepProfileはデータ収集で負荷がかかるので実際の負荷とは違うため(負荷の相対的な比率はだいたい同じ)DeepProfileをオフにした結果を比較します
DeepProfileをオフにしたときの高速化前の負荷

Update 0.42ms
LateUpdate 5.56ms
Rendering 3.2ms
1フレームの処理時間 44.14ms
高速化後の負荷
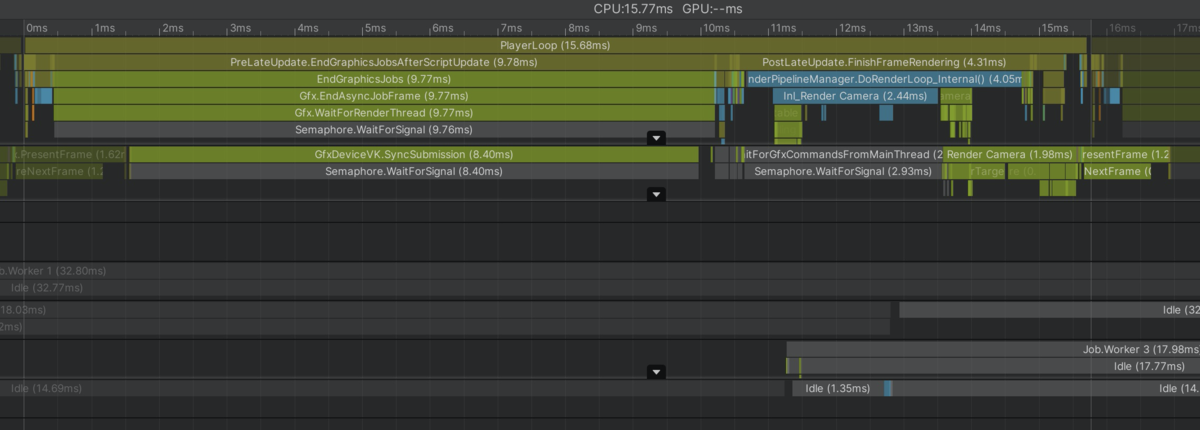
Update 0.00ms
LateUpdate 0.00ms
Rendering 1.6ms(くらい)
1フレームの処理時間 15.77ms
60FPSで問題なく実行できるようになりました
まとめ
一通り紹介しようと思ったら相当長くなってしまいました…
内容もだいぶ飛ばしているので分からない箇所もあると思いますが用語は載せたのでパフォーマンスチューニングする場合はちょっとでも参考になれば幸いです
ちゃんとやれば今のUnityであればいくらでも高速化手段が用意されているのはとてもいいです